
I have been exploring how disk-oriented databases efficiently move data in and out of disk. One way, that I explored in Discovering and exploring mmap using Go and But how, exactly, databases use mmap?, is through memory-mapped files. Although mmap is a really neat solution, it has some troubles. Most troubles come from the fact that the database has no control of how pages are flushed to disk since that job is carried through the OS. Because of that most databases avoid using mmap. However, they still need to read and write data from disk in an efficient manner. And the answer to that is: buffer pool.
In this post, we'll explain how a buffer pool manager works and how to implement one in Go. But first, let's do a simple recap of how data is structured in disk.
How a database file is structured?
The file in disk that stores data of a database is just, in most databases, an array of bytes organized into fixed-length blocks called pages. A database file is a linear array of continuous pages.

The page length is usually a multiple of the filesystem block length ranging from 512 bytes to 16KB. PostgreSQL, for example, uses 8KB, although a different page size can be selected when compiling the server[1]. InnoDB, a storage engine used in MySQL, uses 16KB for page size[2].
The layout of these pages is not the scope of this post. However, just to give a glimpse of what happens when writes are executed, think that, for row-oriented databases, tuples are appended inside the page until it is filled up. When the page is filled up, another page needs to be allocated to support incoming writes.
The buffer pool manager
So we have our data in disk and the database wants to access it, let's say, through a SELECT command. Or we have new incoming data, that we want to store. In order to manage reads and writes efficiently, the common practice is to avoid touching the disk directly. The execution engine that is processing the commands has no access to disk. It has access to an in-memory intermediate layer abstraction called buffer pool.
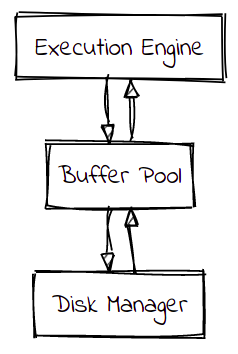
The execution engine requests pages from the buffer pool by providing a page identifier. It can read the content of the page and send the data to the client. Or it can modify the content of the page and send it back to the buffer pool so that the change can be persisted. The execution engine access the buffer pool thinking that it is accessing the disk.
I really think the term buffer pool is kind of misleading here, and it confused me a lot. And that's because the purpose of this structure is not only to manage a pool of empty buffers and its reuse but also it is responsible for caching the disk pages into memory for future reuse (not only by the requesting thread but also for concurrent threads). And as with any cache, also responsible for caching replacement policy. For this reason, a more appropriate name for the buffer pool is page cache. With this in mind, you can imagine the importance of the buffer pool for speeding up the database access to disk.
The buffer pool can be implemented with a statically allocated array of frames. Frames start empty and fill up as pages are being requested. There is an associative structure called page table, that indicates which page is being held by each frame.
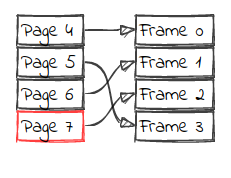
The above image indicates the two data structures used for implementing a buffer pool: a frame array and a page table. The image represents a buffer pool that can cache a maximum of 4 pages. The pages being cached are 4, 5, 6, and 7. The arrows indicate where the page can be found in memory (in the array of frames). Let's look into another buffer pool:
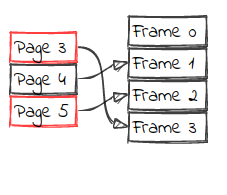
At this, we can see that there are 3 pages in cache, and one space left. The frames that are free and are ready for receiving a new page are tracked in an additional structure called free list.
The pages in red indicate the pages that are being accessed by some thread. That indication is very important because it means that the page cannot leave the buffer pool until all accesses are finished. We will be back to this.
Another important concept is page replacement. What happens when the cache is full, and a page that is not in the cache is requested? We need to evict a page that is not being accessed and give its frame to the requested page. There are many algorithms (or policies) to decide which page to evict. We'll talk about this later.
With these concepts in mind, here is how we can represent our buffer pool in Go code
//BufferPoolManager represents the buffer pool manager
type BufferPoolManager struct {
diskManager DiskManager
pages [MaxPoolSize]*Page
replacer *ClockReplacer
freeList []FrameID
pageTable map[PageID]FrameID
}
//NewBufferPoolManager returns a empty buffer pool manager
func NewBufferPoolManager(DiskManager DiskManager, clockReplacer *ClockReplacer) *BufferPoolManager {
freeList := make([]FrameID, 0)
pages := [MaxPoolSize]*Page{}
for i := 0; i < MaxPoolSize; i++ {
freeList = append(freeList, FrameID(i))
pages[FrameID(i)] = nil
}
return &BufferPoolManager{DiskManager, pages, clockReplacer, freeList, make(map[PageID]FrameID)}
}
The buffer pool receives a DiskManager implementation and a replacer. In our case, we are going to implement the clock replacement policy, implemented by ClockReplacer, for page eviction. Internally, pages represents the frame array of fixed size (MaxPoolSize); pageTable is a map the indicates which frame holds which page; and freeList tracks the array of free frames. Initially, we have all frames ids inside the freeList, because all frames are free. That also means all frames pointing to nil.
And here is the API provided by our buffer pool implementation:
NewPage() *Page
FetchPage(pageID PageID) *Page
FlushPage(pageID PageID) bool
FlushAllPages()
DeletePage(pageID PageID) error
UnpinPage(pageID PageID, isDirty bool) error
NewPage() *Page: a clean new page can be requested. The buffer pool will ask the disk manager for a new page id;FetchPage(pageID PageID) *Page: fetches a known page. If the page is in cache, it is immidiatatly returned. If not, the buffer pool will find it on disk and cache it;FlushPage(pageID PageID) bool: writes the page that is in cache to disk;FlushAllPages()writes all pages in cache to disk;DeletePage(pageID PageID) error: deletes page from cache and disk;UnpinPage(pageID PageID, isDirty bool) error: indicates that the page is not used any more for the current requesting thread. If no more threads are using this page, the page is considered for eviction.
How to represent a page
We are going to represent our page in a very simple manner. Our focus here is to learn how the buffer pool works. Our page is just a []byte followed by an id. There is some metadata that needs to be tracked. One is the pinCount that tracks the number of concurrent accesses. Each time the page is accessed the pinCount is increased. When it is no more in use, the pinCount is decreased. So, if the pinCount is greater than 0, we say the page is pinned and it is indicated in our figures by the red mark. The other metadata variable is isDirty, which indicates that the page has been modified after it was read from disk.
// PageID is the type of the page identifier
type PageID int
const pageSize = 5
// Page represents a page on disk
type Page struct {
id PageID
pinCount int
isDirty bool
data [pageSize]byte
}
The Clock Replacement algorithm
When the buffer pool is full, and a new page needs to enter the cache, some page needs to be chosen to leave the cache. This is a classic cache eviction problem and there is no perfect solution because predicting which pages are going to be requested is a complicated problem. If you can't predict which pages are going to be requested, you don't know which pages must remain in cache and which pages must be evicted. The best you can do is to reduce the number of wrong page evictions. There are many strategies like FIFO (first-in first-out), LRU (least recently used), and LFU (least frequently used). We are not going to explore all of them and their trade-offs. For our buffer pool manager implementation, we have chosen one policy called CLOCK.
When a thread from the execution engine no longer needs a page, it calls the UnpinPage method from the buffer pool. This method reduces the pinCount of the page, and if the pin count reaches zero, the frame id of where that page allocated is stored in the Clock Replacer for future analysis. If, anytime, the same page is accessed again (its pin count increases), and it needs to be removed from the Clock Replacer.
The Clock Replacer keeps tracks of all pages that are not being accessed in a circular buffer. For each page, it also keeps a reference bit to indicate if the page was recently accessed. There is a Clock Hand or Clock Pointer (CP) that iterates through the circular buffer looking for a victim.
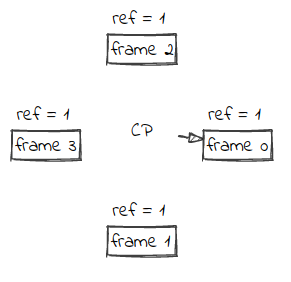
The Clock Replacer provides the following API:
func Victim() *FrameID
func Unpin(id FrameID)
func Pin(id FrameID)
Unpinis called when the buffer pool wants to make a page eligible for eviction because it is no longer accessed;Pinis called when the buffer pool wants to remove a page from cache eviction election because it was accessed and it cannot be evicted;Victimelects a victim through the clock replacement policy.
Let's see how the clock replacement policy works using an example.
The state of the Clock Replacer after the calls Unpin(1), Unpin(2) and Unpin(3).
| num | ref | clock hand |
|---|---|---|
| 1 | 1 | <- |
| 2 | 1 | |
| 3 | 1 |
We have 3 frames eligible for eviction. When Victim() is called, the clock replacement algorithm is run. The clock hand iterates through the circular buffer checking the reference bit. If the bit is set to 1 (that means that the frame was recently added to the clock replacer), it changes the bit to 0. Bellow is how the clock replacer state changes when Victim() is run until it finds a victim for eviction.
| num | ref | clock hand |
|---|---|---|
| 1 | 0 | |
| 2 | 1 | <- |
| 3 | 1 |
| num | ref | clock hand |
|---|---|---|
| 1 | 0 | |
| 2 | 0 | |
| 3 | 1 | <- |
| num | ref | clock hand |
|---|---|---|
| 1 | 0 | <- |
| 2 | 0 | |
| 3 | 0 |
| num | ref | clock hand |
|---|---|---|
| 2 | 0 | <- |
| 3 | 0 |
If we call Unpin(4), we have
| num | ref | clock hand |
|---|---|---|
| 2 | 0 | <- |
| 3 | 0 | |
| 4 | 1 |
And after a call to Victim(), 2 is evicted.
| num | ref | clock hand |
|---|---|---|
| 3 | 0 | <- |
| 4 | 1 |
The clock replacement policy is a very simple implementation that approximates the LRU (least recently used) policy, without the need to track the timestamp of the last time page was accessed. It can be easily implemented using a circular list.
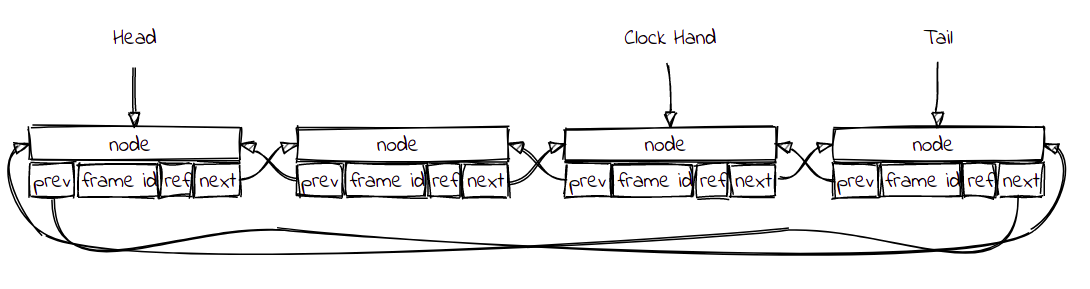
You can check the full implementation at clock_replacer.go.
The Disk Manager
The disk manager is responsible for interacting with the disk. It should be able to read a page from disk, write a page to disk, allocate a new page, and remove a page.
// DiskManager is responsible for interacting with disk
type DiskManager interface {
ReadPage(PageID) (*Page, error)
WritePage(*Page) error
AllocatePage() *PageID
DeallocatePage(PageID)
}
Since our main concern was the buffer pool, in our demo we implemented an in-memory mock of the disk manager, that can be checked at disk_manager_mock.go.
Implementing the Buffer Pool
Let's dissect the FetchPage, NewPage and ÙnpinPage methods. The other methods are pretty straightforward, and you can check full code at the repo.
Fetching a page
First, we check if the page is in the buffer pool. If we can find the page in the cache, we increase the pin count (to indicate there is one more thread accessing the page) and make sure it not in the clock replacer by calling Pin.
if frameID, ok := b.pageTable[pageID]; ok {
page := b.pages[frameID]
page.pinCount++
(*b.replacer).Pin(frameID)
return page
}
If it is not in the buffer pool we need to find a frame to allocate this page. The buffer pool can have free frames or it can be full. The getFrameID method handles this. We check our freeList to see if there are any frames available. If we can find an empty frame, we return its id and remove it from freeList. If we can't find an empty frame, we have to elect a frame from the buffer pool to free space by running the clock replace algorithm. The bool indicates if the frame id came from the free list or from the eviction algorithm.
func (b *BufferPoolManager) getFrameID() (*FrameID, bool) {
if len(b.freeList) > 0 {
frameID, newFreeList := b.freeList[0], b.freeList[1:]
b.freeList = newFreeList
return &frameID, true
}
return (*b.replacer).Victim(), false
}
Now that we have a frame id and it didn't come from freeList, we have to remove the page that is allocated in that frame. But if the page was modified (isDirty set to true), then we have to first write it to disk.
if !isFromFreeList {
// remove page from current frame
currentPage := b.pages[*frameID]
if currentPage != nil {
if currentPage.isDirty {
b.diskManager.WritePage(currentPage)
}
delete(b.pageTable, currentPage.id)
}
}
Finally, we read the page from disk and allocate it to the chosen frame id
page, err := b.diskManager.ReadPage(pageID)
if err != nil {
return nil
}
(*page).pinCount = 1
b.pageTable[pageID] = *frameID
b.pages[*frameID] = page
Requesting a new page
Requesting a new page follows the same logic as fetching a page. We need to make sure there is space for a new page in the buffer pool by checking the free list or by replacing a page. After that, the buffer pool requests the disk manager a new page and put it in the cache.
// allocates new page
pageID := b.diskManager.AllocatePage()
if pageID == nil {
return nil
}
page := &Page{*pageID, 1, false, [pageSize]byte{}}
b.pageTable[*pageID] = *frameID
b.pages[*frameID] = page
Indicating that a page is no longer accessed
After some work is done by a thread on a page, it needs to call the UnpinPage method to indicate the buffer pool that it not using that page anymore. This call is important because it lets the buffer pool decide if that page can be considered for eviction.
The method decreases the pin count of the page. If the pin count reaches 0, it means that there is no thread accessing that page. So, that page is added to the clock replacer to be considered for eviction.
page := b.pages[frameID]
page.DecPinCount()
if page.pinCount <= 0 {
(*b.replacer).Unpin(frameID)
}
A visualization tool
I was not satisfied with only implementing the buffer pool. I wanted to able to visualize it working. So I went on a mission to build a small JavaScript application that could interact with the buffer pool. I built a web server that instantiated a buffer pool and could receive HTTP requests and send commands to the buffer pool.
Here is a small demo:

You can see four initial calls of New Page, loading all frames of our buffer pool. We flush all the pages to disk. Flushing the pages to disk reduces the pin count of all pages by one (that's why they go from red to black). After that, Unpin is called to pages 2 and 3, adding both respective frames to the clock replacer. Delete is called for page 2, removing it from the clock replacer, the buffer pool, and the disk, causing a disk fragmentation. New page is called, and page 4 enters the buffer pool in the free frame 2. New page is called again, but the buffer is full. The clock replacement algorithm runs and frees frame 3 for page 5, evicting page 3. Flush all is called writing pages 4 and 5 to disk. Fetch Page is called on page 0 twice, increasing the pin count by two. That means that the Unpin needs to be called twice, in order to make it eligible for eviction. Last, New Page is called, but the buffer is full again. After the clock replacement algorithm is run, page 6 goes to frame 0.
You can play yourself by following the instructions at the repo.
Final thoughts
I have been studying databases for awhile mainly through the course Intro to Database Systems of Andy Pavlo. In the course, he talks about how mmap is most of the time a bad idea for solving the "data in disk larger than the available memory" problem and introduces the concept of buffer pool. One of the assignments is to implement a buffer pool manager in C++. That's where the idea of implementing one in Go came from.
Even though mmap and buffer pool are two completely different implementations to solve the same problem, I have come to found both very similar. The buffer pool acts like it has all pages in memory, and if the page is not in the cache, it removes one from the cache and fetches the page from the disk putting it on the cache. Pretty much the same logic of the virtual memory that is behind the mmap call. The difference in the buffer pool approach is that everything is in control. The way pages are flushed, locked, and evicted from cache is controlled by the buffer pool. And this kind of control, you completely lose with mmap. And that is why is not to be recommended unless you really know what you are doing.
A buffer pool is supposed to be a shared resource and it is meant to be used by multiples threads doing queries at the same time. In this implementation, it was not our focus to build a thread-safe buffer pool protecting the data structures from race conditions. A thread-safe implementation is planned.
I am on a journey to learn more about databases by implementing parts of one. If you like this kind of content, follow me on Twitter. I will be sharing more related stuff.
Full code at brunocalza/buffer-pool-manager.
Learn more
- CS186Berkeley Playlist on Buffer Management
- Intro to Database Systems
- Architecture of a Database System
References
[1] 68.6. Database Page Layout
[2] 14.8.1 InnoDB Startup Configuration