
In a previous post Discovering and exploring mmap using Go, we talked about how databases have a major problem to solve, which is: how to deal with data stored in disk that is bigger than the available memory. We talked about how many databases solve this problem using memory-mapped files and explored mmap capabilities.
Knowing that databases use memory-mapped files to solve the problem was not enough for me. It solved part of the mystery but a question remained: how, exactly, databases use mmap to read and write data from disk?
I decided to dig through a database source code to answer that question. There are plenty of databases that use mmap. Some of them decided to not use anymore. Some examples: SQLite has an option of accessing disk content directly using memory-mapped I/O[1], it seems LevelDB used to use but it changed it[2], Lucene has an option with MMapDirectory[3], LMDB uses mmap[4], a simple key/value in-memory database from Counchbase called moss uses mmap for durability of in-memory data[5] and MongoDB removed mmap storage engine for WiredTiger[6].
I chose bolt, a simple key/value store implemented in Go by Ben Johnson inspired by the LMDB project, for this endeavor. Mostly because of source code simplicity and my familiarity with Go language. I know a simple key/value store might not be the most complete source code for learning all the details of reading/writing data to disk, but as I have found out, it was more than enough to get a grasp of it.
The original bolt repository is no longer maintained. A fork of bolt called bbolt is maintained and used by etcd. If you are not familiar with bolt, I recommend the articles Intro to BoltDB: Painless Performant Persistence and Bolt — an embedded key/value database for Go .
The start
I download the code to my machine and opened it in my editor. I thought a good place to start digging was to find out where the database was initialized and look for any references of mmap there. Like most embedded databases, bolt has an Open method for opening the database or creating a new one if it does not exist. Inside it, I found a reference to a private mmap function. That's a good start.
// Memory map the data file.
if err := db.mmap(options.InitialMmapSize); err != nil {
_ = db.close()
return nil, err
}How much memory should I allocate?
The private mmap is responsible for opening the memory-mapped file. In order to do this, it needs to figure out how much memory it is going to allocate. This task is accomplished by another method called mmapSize. Given the size of the database, this method figures out how many bytes of memory should be allocated.
It starts by doubling the size from 32KB to 1GB. But if the database is larger than 1GB, it grows 1GB at a time.
// Double the size from 32KB until 1GB.
for i := uint(15); i <= 30; i++ {
if size <= 1<<i {
return 1 << i, nil
}
}
...
// If larger than 1GB then grow by 1GB at a time.
sz := int64(size)
if remainder := sz % int64(maxMmapStep); remainder > 0 {
sz += int64(maxMmapStep) - remainder
}It is all fine by now. That's how bolt figured out how much to allocate. But there is a piece of the puzzle now that will be very important when we talk about database storage layout. After figuring out how much to allocate, it needs to ensure that the allocated size is a multiple of the page size. If you are not familiar with database storage and don't know what a page is, don't worry, we'll be back to this.
// Ensure that the mmap size is a multiple of the page size.
// This should always be true since we're incrementing in MBs.
pageSize := int64(db.pageSize)
if (sz % pageSize) != 0 {
sz = ((sz / pageSize) + 1) * pageSize
}Shouldn't it check if we are allocating more than we have available? That's the last piece of the mmapSize method.
// If we've exceeded the max size then only grow up to the max size.
if sz > maxMapSize {
sz = maxMapSize
}The maxMapSize constant is set to 0xFFFFFFFFFFFF on AMD64 architectures.
The AMD64 architecture defines a 64-bit virtual address format, of which the low-order 48 bits are used in current implementations. This allows up to 256 TiB (248 bytes) of virtual address space. - x86-64 Wiki
This is the limit of the bolt database file.
Calling the system call
Now that bolt knows how much it should allocate, it calls the system call mmap. Here is the full code for Unix-like environments:
// mmap memory maps a DB's data file.
func mmap(db *DB, sz int) error {
// Map the data file to memory.
b, err := syscall.Mmap(int(db.file.Fd()), 0, sz, syscall.PROT_READ, syscall.MAP_SHARED|db.MmapFlags)
if err != nil {
return err
}
// Advise the kernel that the mmap is accessed randomly.
if err := madvise(b, syscall.MADV_RANDOM); err != nil {
return fmt.Errorf("madvise: %s", err)
}
// Save the original byte slice and convert to a byte array pointer.
db.dataref = b
db.data = (*[maxMapSize]byte)(unsafe.Pointer(&b[0]))
db.datasz = sz
return nil
}It is a pretty straightforward code. I have some observations to make about syscall.PROT_READ, but I'll leave for the next session. It is nice to see the call to madvise there, although I don't know its benefits. I would love to know the importance of that call, if it improves performance or if another flag could be set to get different behavior from OS for different use cases.
The mapped memory is set to the variables db.dataref and db.data.
db.dataref = b
db.data = (*[maxMapSize]byte)(unsafe.Pointer(&b[0]))
I would like to know about the importance of keeping track of both variables. I could not grasp what is going on in the conversion to db.data. But anyway, what we have to keep in mind is that is through these variables that bolt will read data from disk.
What about writes?
While skimming through the source code, I looked for evidence of how mmap was used for both reads and writes. I dug both Get and Put method. I could not find any place where the references to db.dataref or db.data were being updated. I discovered that the writes to disk happen when Commit is called to a transaction. But there I could only find calls to WriteAt. So I gave up my search of trying to understand how mmap was used for writes.
Then, suddenly, while looking back to the call of mmap, I noticed the syscall.PROT_READ flag that I have not noticed the first time I looked at the code. So mmap, is only used for reads in bolt. Another place that indicates this is in the definition of DB struct:
dataref []byte // mmap'ed readonly, write throws SEGV
data *[maxMapSize]byteThat made perfect sense to me. Since flushes to disk are very hard to control when using mmap, it is probably the safest approach. How bolt does writing is a topic of another post.
How the database file is structured?
We know how and when bolt allocates memory and that mmap is not used for writes. But how, exactly, bolt can find the value of a key? To understand that, we have to understand how typically databases structure their files. I am not going to do deep here. Mostly because I don't understand enough to go deep. Just going to try to give a glimpse of what is going on.
A file is just an array of bytes. We have to apply some reasoning to this array of bytes to work with it effectively. Databases structure their files in disk into blocks (chunks of bytes) called pages. bolt is no different. The database file can be seen as
Each page has a fixed length of bytes, typically the same size as the OS page (usually 4096 bytes). Here is the part of bolt that sets the pageSize.
// default page size for db is set to the OS page size.
var defaultPageSize = os.Getpagesize()
Every database has its own page layout. The page layout of bolt is defined at page.go as
const (
branchPageFlag = 0x01
leafPageFlag = 0x02
metaPageFlag = 0x04
freelistPageFlag = 0x10
)
const (
bucketLeafFlag = 0x01
)
type pgid uint64
type page struct {
id pgid
flags uint16
count uint16
overflow uint32
ptr uintptr
}
id: it is the page identifier used to index the page. Given a page id, I can locate it in the disk through mmap, since the disk file is just a list of continuous fixed length pages;flags: it tells the page type. There are four types of page:meta,freeList,leafandbranch;count: indicates the number of elements stored in the page;overflow: represents the number of subsequent pages;ptr: indicates the end of page header and start of page data. This is where the keys and values are going to be stored.
A visual representation of a page:
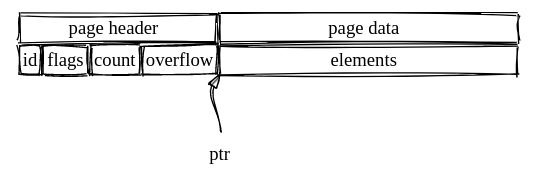
With this in mind, we can look at the code that retrieves a page given its id.
// page retrieves a page reference from the mmap based on the current page size.
func (db *DB) page(id pgid) *page {
pos := id * pgid(db.pageSize)
return (*page)(unsafe.Pointer(&db.data[pos]))
}How to perform an efficient search?
We know how the database file is structured in disk and we know how to retrieve a page from disk. But how a bucket.Get([]byte("key")) search works? We are not going to go into too much detail here. I hope the abstraction I created will be enough to get a clue about what is going on.
What if the pages themselves, in the data part, contained references to other pages? And what if these references build up to form a B+Tree?
That is exactly what bolt does. Thinking of the page as a node of a B+Tree. In a B+Tree we have internal nodes and leaves. That's the reason for the `flags` attribute, to indicate what kind of node that page is.
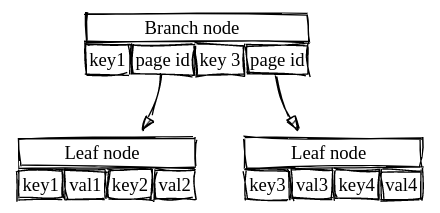
So to perform the search of a key, you start at the root node a do a B+Tree traversal on mmapped disk pages. Therefore, bolt is a memory-mapped B+Tree file. The more memory you have, the more it will behave like a memory key/value store.
There are many more details about this process. Most of it I don't understand myself. So let's just keep it simple at this abstract level.
Resizing mmap
When I started looking at the source code, I searched for all calls of mmap. The first was found at the Open method, as explained in the beginning. And the second one was found at the allocate method.
When bolt is writing it needs to make sure it is not consuming all the allocated memory. If it sees that it is going to exceed the database size, it resizes the memory.
// Resize mmap() if we're at the end.
p.id = db.rwtx.meta.pgid
var minsz = int((p.id+pgid(count))+1) * db.pageSize
if minsz >= db.datasz {
if err := db.mmap(minsz); err != nil {
return nil, fmt.Errorf("mmap allocate error: %s", err)
}
}Conclusion
Reading bolt source code is a very nice way of understanding database internals. It was not very intimidating as I thought it would be. We ignored most of its source code, trying to focus only on how mmap is used to retrieve data from disk efficiently. There are so many more concepts we can learn from bolt like transactions, atomic, isolation, concurrency control, but I'll leave for another posts.
It is important to remind that the strategy used by bolt is just one of multiple strategies. Others databases uses different page layouts and different data structures. However, on a higher level the logic of mmapped databases should be the same I guess.
I am on a journey to learn more about databases. If you are interested you can follow me on twitter, where I share more related content.
If you want to learn more about bolt
- Boltdb source code analysis
- BoltDB for block persistence (1)
- Go-nuts and Bolts: An Introduction to BoltDB
References
[1] Memory-Mapped I/O
[2] mmap based writing vs. stdio based writing
[3] Memory-mapped files with Lucene: some more aspects
[4] PERFORMANCE TRADEOFFS IN LMDB
[5] Marty Schoch - Building a High-Performance Key/Value Store in Go
[6] Storage Engines