
In computing, caching is all over the place. It is found in hardware (CPU and GPU), operating system's virtual memory, buffer pool managers inside databases, in the Web (Content Delivery Networks, browsers, DNS servers ...), and also inside the applications we build. In this post, we take an abstract look of what cache is, the replacement problem that arises from cache's own nature and some algorithms for implementing cache replacement policies.
Defining Cache
Independently of the context of where caching is being applied, the pure reason for its existence is to a system have better performance than it would without the cache. A system works "fine" without caching. It is just that by applying this technique the system performs better. And, in the context of caching, perform better means accessing the data that is needed faster.
In order to achieve the performance gain, part of the data is replicated to a secondary storage. Instead of accessing the data through the primary storage, the system accesses through the cache; and the access through the cache is supposed to be more performative. The performance gain of accessing this different storage may arise for multiples reasons. It can be for a technological one. For example, the data in the cache is in memory and the primary storage uses a disk. It can be to avoid overheads. For example, the primary storage can be a relational database, and you add a cache to avoid the overhead of connecting to the database, parsing the SQL query, accessing the disk, and transforming the results to the format that suits the client application. It can be for geographical reasons, as in the case of Content Delivery Networks.
One of the main drivers of why the cache contains only a subset of the primary storage is cost. Maintaining a copy of the entire primary storage may be too costly, so we have to content ourselves with a cache of limited capacity. More importantly, by design, a cache is supposed to have small sizes. That's because the whole purpose of caching is to optimize for data access. Most of the data is not accessed, so keeping in cache a subset of data that is frequently accessed is what allows faster look-ups. With all this in mind, let's define cache, for the purposes of this post, as:
A secondary storage with limited capacity that contains a copy of a subset of the data that is stored in main storage.
By copy here, I don't mean exactly copy. Data stored in cache can be the result of computation like the database example talked about above.
The "Cache is Full" Problem
What would be the optimal performance of a cache design? Every time that data needs to be accessed, it can be found in the cache (cache hit). But since the cache is only a subset, it means that sometimes data won't be found in cache (cache miss). If the data that is not in the cache is never requested, it doesn't really matter if it is not in the cache. So, as cache designers, we have to make a decision of what data should we keep in the cache and what data should we keep out of the cache in order to maximize the cache hit (or minimize cache miss).
To make things clear and for the sake of the discussion let's assume the following while interacting with the cache:
- The cache starts empty;
- The application always interacts with the cache first. If it doesn't find the data that is looking for (Get operation), it consults the primary storage, then it adds to the cache (Put operation), as in the figure below;
- The entries inside the cache never expires (there is no TTL);
- The entries in the cache are always up-to-date.
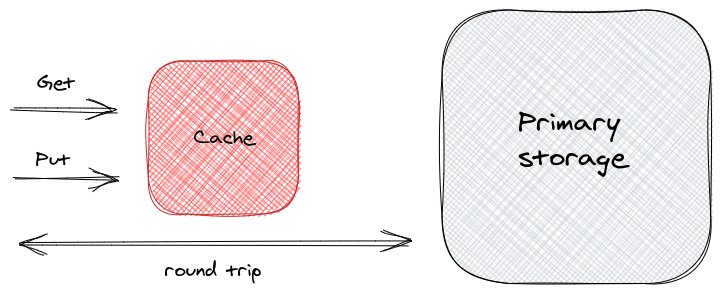
There are multiple architectural options on how to interact with the cache. That is not the point to be discussed here. The point is what data should we keep in cache. From the above figure, there are two points where we have to make a decision of what data lies in the cache. The first point in the Put operation. The client doesn't need to add every missed entry to the cache, it can wisely choose those that make more sense. The second decision point is when the client decides to add an entry to the cache but the cache is full. Full may mean that the numbers of entries reached maximum capacity or that the cache has reached its maximum pre-defined storage or any other criteria that are more relevant to your scenario. When that happens, a decision on what existing entry needs to be evicted from cache to make room for a new entry has to be made. This decision-making process, which is the topic of interest in the post, is called cache replacement policy.
Cache Replacement Policies
The problem of choosing an entry to discard from cache can be re-framed as discarding the entry that is least likely to be used in the future. This is not an easy problem, because we can't predict which entries are not going to be needed in the future. If we could predict, we'd have an optimal algorithm.
Cache replacement policies rely on heuristics that are dependent on the context. A policy for a CPU cache will probably differ from the policy of web caching. Hardware caching may impose architectural restrictions that may be not found on the web. Besides that, the parameters that are aimed for optimization influence a lot on the chosen algorithm. The most common parameter that is attempted to maximize is the hit ratio. Some other parameters that can be considered for optimization are byte hit ratio, cost of access, and latency.
In addition, these policies can make use of characteristics of the cache entry to base a decision. Some of the most popular characteristics are:
- recency: time of (since) the last reference to the entry;
- frequency: number of requests to an entry;
- size: the size of the entry;
- cost of fetching the object: cost to fetch an object from its origin;
Because of the context, the parameters that are being optimized, and the information used in the heuristics, an enormous variety of replacement algorithms arose. We are going to focus on FIFO, LRU, CLOCK, and LFU to get a full understanding of how a replacement policy typically works.
Implementing Some Policies in Go
The cache
We are going to make clear distinctions about the core logic of the cache and the logic of the replacement policy. Not only that, we are going to have multiples policies that implement the same policy interface. This way it makes it easier to swap implementations to see how the policies differ from one another. In practice, such decoupled implementation adds some memory overhead (you need an additional hash table) and it is quite hard to have an interface that abstracts all possible caching policies. In our case, the abstraction works because the chosen algorithms are somewhat related.
Our cache is going to be represented by
type CacheKey string
type CacheData map[CacheKey]string
type Cache struct {
maxSize int
size int
policy CachePolicy
data CacheData
}
For simplicity will have both the key and the value as string. There is one attribute, size, for keeping track of the cache's size and another indicating its capacity, maxSize. It has a policy, that will be responsible for evicting cache entries when the cache is full. Lastly, it uses a hash table for storing the cache entries.
A cache policy is defined as
type CachePolicy interface {
Victim() CacheKey
Add(CacheKey)
Remove(CacheKey)
Access(CacheKey)
}
Victimruns the policy algorithm and elects aCacheKey, called victim, for removal;Addmakes a cache key eligible for evictionRemovemakes a cache key no longer eligible for evictionAccessindicates to the cache policy that a cache key was accessed. This provides additional information to the cache replacement algorithm to make its decision
By decoupling the core logic of the cache and the replacement logic, it is very easy to understand how a cache works. Here is the Put operation
func (c *Cache) Put(key CacheKey, value string) {
if c.size == c.maxSize {
victimKey := c.policy.Victim()
delete(c.data, victimKey)
c.size--
}
c.policy.Add(key)
c.data[key] = value
c.size++
}
If the cache is full, it calls the replacement policy Victim that runs the algorithm and returns a cache key for eviction. The cache, then, removes the cache entry making room for the new key. The Get operation is straightforward. If it finds the key in the cache, it indicates to the key was accessed and returns the cached value.
func (c *Cache) Get(key CacheKey) (*string, error) {
if value, ok := c.data[key]; ok {
c.policy.Access(key)
return &value, nil
}
return nil, errors.New("key not found")
}
We have a cache implementation. Now let's focus on the replacement policies.
FIFO
FIFO (First In First Out) is one of the simplest algorithms. It simply removes the entries in the order that they were added. So, the decision that the algorithm does is: choose the oldest entry in the cache for removal.
It can be easily implemented using a queue. A O(1) queue is usually implemented using a doubly linked list . We are going to really on Go's container/list implementations of a doubly-linked list.
Here is the FIFO policy definition
type FIFOPolicy struct {
list *list.List
keyNode map[CacheKey]*list.Element
}
We are going to make use of an additional hash table, to make it possible to make the Remove method implementation O(1). If you add 5 elements to the cache, the FIFO queue will look like this:
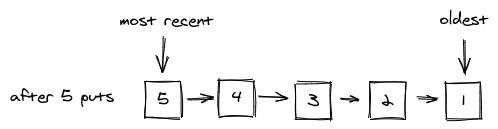
queueChoosing a key for eviction is as simple as choosing the element that lies at the tail of the list. The methods' implementations are just simple list operations.
func (p *FIFOPolicy) Victim() CacheKey {
element := p.list.Back()
p.list.Remove(element)
delete(p.keyNode, element.Value.(CacheKey))
return element.Value.(CacheKey)
}
func (p *FIFOPolicy) Add(key CacheKey) {
node := p.list.PushFront(key)
p.keyNode[key] = node
}
func (p *FIFOPolicy) Remove(key CacheKey) {
node, ok := p.keyNode[key]
if !ok {
return
}
p.list.Remove(node)
delete(p.keyNode, key)
}
One interesting thing is the implementation of the Access method, which is empty. Since the FIFO policy does not rely on access patterns to make its decision, the Get operation has no effect on the algorithm.
func (p *FIFOPolicy) Access(key CacheKey) {
}
LRU
LRU (Least Recently Used) is one of the most popular cache replacement policies. If an item is in the cache for a long time but was used recently, it will probably not be elected. The items that have not been used for a while are the ones considered for eviction.
If you think about it, this algorithm is very similar to the FIFO algorithm. We just have to take into account the fact that an entry was used recently. In fact, this algorithm can be implemented identically as the FIFO, excepts for the Access method.
func (p *LRUPolicy) Access(key CacheKey) {
p.Remove(key)
p.Add(key)
}
The LRU relies on access patterns. Every time a cache entry is accessed, we update the recency of the cache key in the policy by removing the key from the queue and pushing it to the front, where the most recent item lies.
Let's do some calls and how the internal LRU queue behaves.
cache := NewCache(5, LRU)
cache.Put("1", "1")
cache.Put("2", "2")
cache.Put("3", "3")
cache.Put("4", "4")
cache.Put("5", "5")
cache.Get("3")
cache.Get("1")
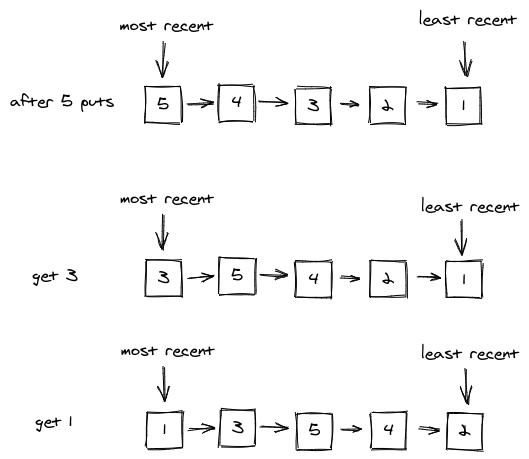
changes after the Get operationIf we call cache.Victim() now, it will choose 2 which is the least recent.
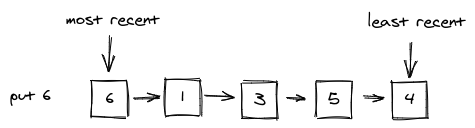
CLOCK
In some situations, the LRU policy is not considered because accessing a cache entry involves removing the entry from the back of the list and reinserting it at the front. For an operating system, this operation is very costly. Since the LRU is generally considered a good policy, alternatives that approximate it are used instead. One of the alternatives is called CLOCK. Like the LRU, it is an improvement from FIFO. However, it avoids the costly operation of manipulating the list on every access making use of a circular list (hence the name CLOCK) a reference bit to indicate that the entry was recently accessed. Here is the representation of its data structure.
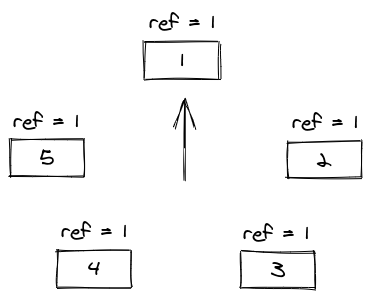
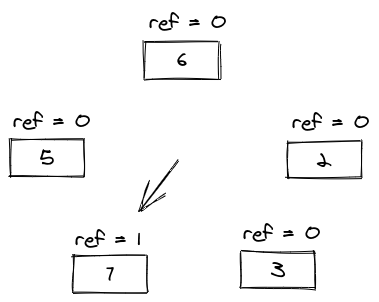
The eviction algorithm makes use of a clock pointer to traverse the circular list in search of an entry that has the reference bit set to 0 (ref = 0). Every time that it checks the reference bit, if it is set to 1, it sets it to 0 and goes for the next entry. To illustrate this, let's look at the state of the clock after adding entry 6 at the above clock.
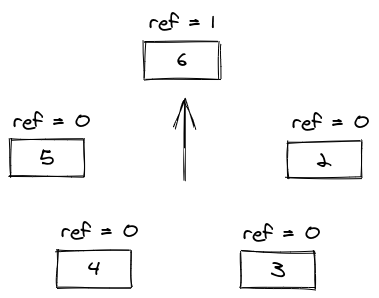
Using Redis as an LRU cache
It will traverse the circular list setting every reference bit to 0 until it reaches the first entry of reference bit 0, which will be entry 1. It will evict the 1, to make room for the 6. Now let's do two Get operations: Get 2 and Get 3. They are going to set the reference bit to 1.
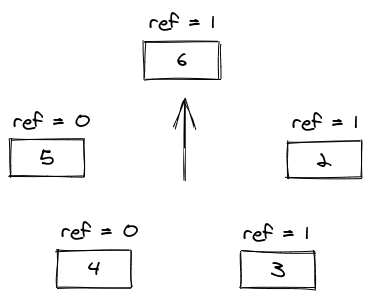
When we look at the implementation of the Access method, it is clear that there is no need to manipulate the list as the LRU did. It directly accesses the node and changes its reference bit.
func (p *ClockPolicy) Access(key CacheKey) {
node, ok := p.keyNode[key]
if !ok {
return
}
node.Value = &ClockItem{key, true}
}
If we try to add a new entry 7 now, it will set the reference bits of 6, 2, and 3 to 0, and then evict entry 4.
Here is how we represent the policy in code:
type ClockItem struct {
key CacheKey
bit bool
}
type ClockPolicy struct {
list *CircularList
keyNode map[CacheKey]*ring.Ring
clockHand *ring.Ring
}
CircularList is an implementation that makes use of container/ring, Go's implementation of a circular list.
And the Victim method described above is implemented with a for loop that advances the clock hand checking the references bit.
func (p *ClockPolicy) Victim() CacheKey {
var victimKey CacheKey
var nodeItem *ClockItem
for {
currentNode := (*p.clockHand)
nodeItem = currentNode.Value.(*ClockItem)
if nodeItem.bit {
nodeItem.bit = false
currentNode.Value = nodeItem
p.clockHand = currentNode.Next()
} else {
victimKey = nodeItem.key
p.list.Move(p.clockHand.Prev())
p.clockHand = nil
p.list.Remove(¤tNode)
delete(p.keyNode, victimKey)
return victimKey
}
}
}
You can check how the clock replacement can be used in a buffer pool manager at How Buffer Pool Works: An Implementation In Go.
LFU
The LFU (Least Frequently Used) cares more about frequency than recency. It relies on how many accesses an entry had, which means that somehow the algorithm needs to keep track of the frequency count. Historically, the most popular implementation uses a min-heap to keep track of the least frequently used entries. A heap is a good data structure choice, but it offers O(log n) operations. We are going to implement an algorithm with O(1) operations, by keeping a hash table the maps the frequency to a doubly-linked list. Each frequency has its own queue. Just because this implementation is O(1) it doesn't mean it better. It has additional memory costs that may not be appropriate depending on the context.
Here is the LFU policy definition:
type Frequency int
type LFUItem struct {
frequency Frequency
key CacheKey
}
type LFUPolicy struct {
freqList map[Frequency]*list.List
keyNode map[CacheKey]*list.Element
minFrequency Frequency
}
We are going to store an LFUItem as the value of the list element. The LFUItem contains the frequency, which is helpful when updates to the frequency list need to be made. The minFrequency keeps track ofImplementations the minimum frequency that can be found. That is helpful to locate the list from which some element will be chosen to evict.
Here is a representation of how the algorithm works (from left to right) showing the state of the frequency list after some operation.
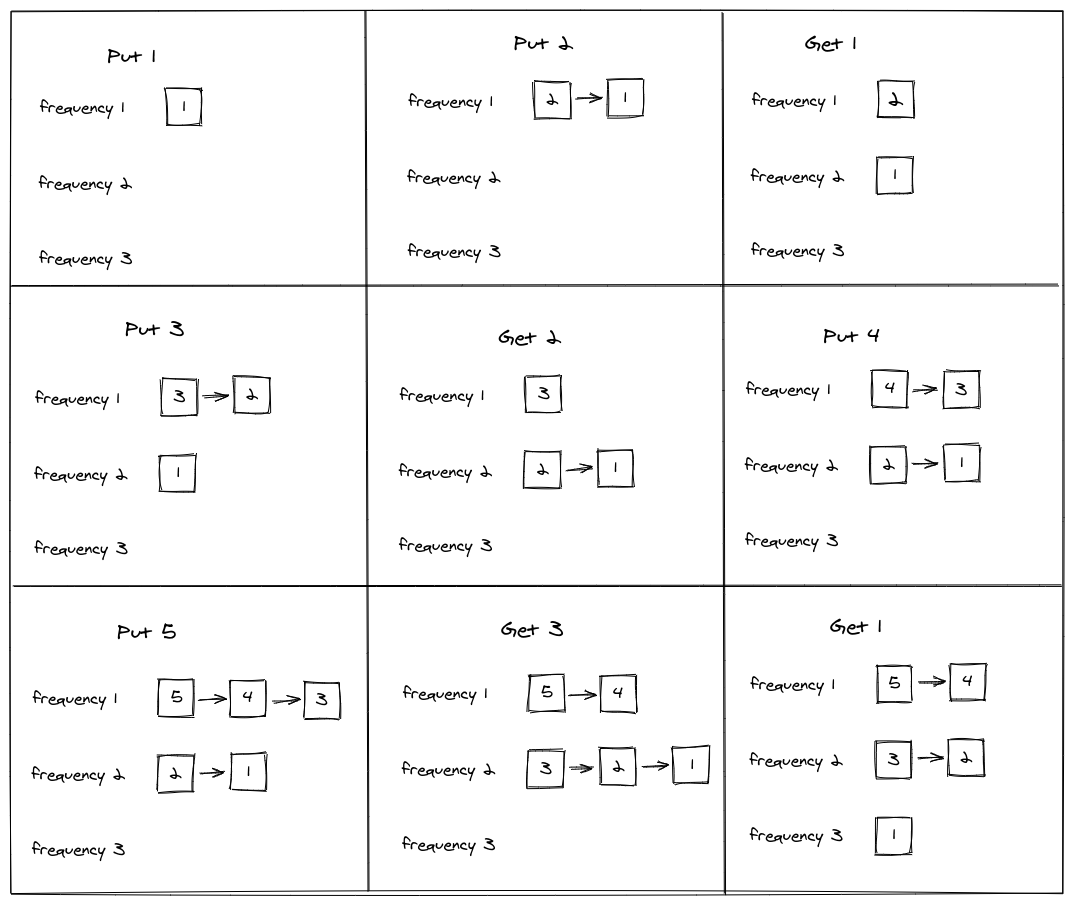
Adding a new entry to the cache means pushing the cache key of that entry to the front of the queue of freqList[1]. Frames 1, 2, 4, 6, 7 show that. Here is the implementation.
func (p *LFUPolicy) Add(key CacheKey) {
_, ok := p.freqList[1]
if !ok {
p.freqList[1] = list.New()
}
node := p.freqList[1].PushFront(LFUItem{1, key})
p.keyNode[key] = node
p.minFrequency = 1
}
When a Get operation occurs, it follow that we need to remove the element where it currently lies and push to the front of list stored at the freqList[frequency + 1].
func (p *LFUPolicy) Access(key CacheKey) {
node := p.remove(key)
frequency := node.Value.(LFUItem).frequency
_, ok := p.freqList[frequency+1]
if !ok {
p.freqList[frequency+1] = list.New()
}
node = p.freqList[frequency+1].PushFront(LFUItem{frequency + 1, key})
p.keyNode[key] = node
}
Lastly, the element the is chosen for eviction is the one that lies at the tail of the minFrequency list. In our example, would be entry 4. And here is how to implement it:
func (p *LFUPolicy) Victim() CacheKey {
fList := p.freqList[p.minFrequency]
element := fList.Back()
fList.Remove(element)
delete(p.keyNode, element.Value.(LFUItem).key)
return element.Value.(LFUItem).key
}
Final Considerations
In this post, we tried to take an abstract look at the cache and what happens when the cache is full. We discussed and showed how to implement 4 popular cache replacement policies, that can be found at brunocalza/cache-replacement-policies. The aim of this post was not to discuss the trade-offs or in which circumstances one approach is better than another. That is a huge topic and full of nuances. Having said that if you know how these techniques are applied in real systems feel free to share. Consider following me on Twitter, if you enjoy the content.
Further Materials and References
- Meizhen, Weng, Shang Yanlei, and Tian Yue. "The design and implementation of LRU-based web cache." 2013 8th International Conference on Communications and Networking in China (CHINACOM). IEEE, 2013.
- Podlipnig, Stefan, and Laszlo Böszörmenyi. "A survey of web cache replacement strategies." ACM Computing Surveys (CSUR) 35.4 (2003): 374-398.
- Balamash, Abdullah, and Marwan Krunz. "An overview of web caching replacement algorithms." IEEE Communications Surveys & Tutorials 6.2 (2004): 44-56.
- Wikipedia Cache (computing)
- Wikipedia Page Replacement Algorithm
- Clock Page Replacement
- HashiCorp LRU's library: hashicorp/golang-lru
- Caching in theory and practice
- Least Frequently Used (LFU) Cache Implementation
- Constant Time LFU
- When and Why to use a Least Frequently Used (LFU) cache with an implementation in Golang
- Using Redis as an LRU cache