Implementing Snowflake Unique ID Generation
Apr 07, 2026This post is part of a series on Fly.io’s distributed systems challenges:
- Implementing Snowflake Unique ID Generation (this post)
- Generating Unique IDs with Raft Consensus
- Fly.io’s Broadcast Challenges
- Building a Grow-Only Counter on a Sequentially Consistent KV Store
I’ve wanted for some time to work on this series of distributed systems challenges by Fly.io, and I have finally found some time. This post is about Challenge #2: Unique ID Generation.
A brief explanation of what these challenges are all about for those not familiar. In essence, you are given a task to build a decentralized algorithm that should pass a test. You use maelstrom as the platform that provides the workload and checks if the results generated by your algorithm are valid for that workload. To give you a sense of how that works, here’s the command I’ve run for project 2:
./maelstrom test -w unique-ids \
--bin ~/go/bin/maelstrom-unique-ids \
--node-count 5 \
--time-limit 30 \
--rate 1000 \
--availability total \
--concurrency 10 \
--nemesis partition
You run a maelstrom test specifying the workload, in this case unique-ids. You provide your task as a binary, e.g. ~/go/bin/maelstrom-unique-ids. You can set some parameters that influence how the test is run:
-
node-count: the number of processesmaelstromwill spawn of your binary -
time-limit: for how long the test runs -
rate: requests/s -
concurrency: clients running concurrently -
nemesis: inject a fault, in this case a network partition -
availability: the availability target that will be checked
Generating unique ids is a common problem in distributed systems and it is not particularly hard to solve, and for this challenge you can get a valid result pretty easily with solutions such as:
-
Use the node id as the namespace, and a sequence counter per namespace
-
Generate an UUID or ULID
-
Use a centralized database as the provider of the sequence
There are two approaches I wanted to explore for fun: implementing Twitter Snowflake and using a consensus algorithm. I mean, the idea is not just to pass the challenge but learn a bit more about the problem, alternative solutions, and trade-offs. In this post, I focus more on Snowflake, and hopefully I’ll write another one about using consensus.
It is kind of interesting to see their motivation in that blog post. They were using Cassandra, which had no built-in way of generating unique ids, and they needed an id that was roughly sortable, highly available, and had to fit into 64 bits. Interestingly enough, none of the solutions we listed above worked for them.
The solution was the following composition:

You have a sequence scoped by node id, and timestamp. The algorithm runs as follows:
-
Every time a new id is requested on a node (e.g. node
0), it grabs the current timestamp, e.g.1775566509000, if this timestamp is different from the last timestamp used when an id was generated thesequenceis reset.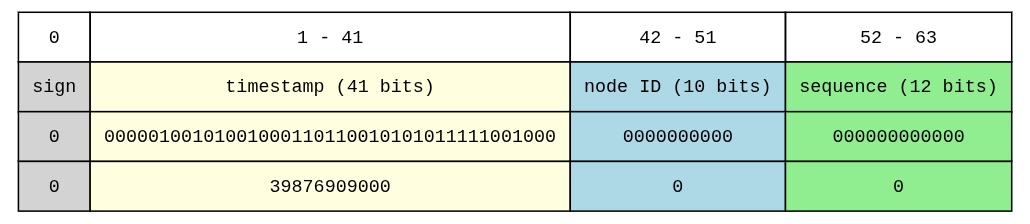
The timestamp in this algorithm is the number of milliseconds since a custom epoch. I am using
1735689600000as the custom epoch, so that’s why we use39876909000 = 1775566509000 - 1735689600000Also, 41 bits of timestamp is roughly 69 years. That means, Twitter has 69 years after their chosen epoch time before this algorithm expires.
-
If a new id is requested at the same timestamp,
sequenceis increased. Sosequenceis only increased when two requests happen at the same millisecond. Meaning we can have at most 4096 (12 bits) requests per millisecond in that node. -
If it happens to be the case that we have more than 4095 requests, and
sequenceoverflows, the algorithm waits for the next millisecond and resets the sequence.
So, I implemented this algorithm for the challenge.
package main
import (
"sync"
)
const (
nodeBits = 10
seqBits = 12
maxNodeID = (1 << nodeBits) - 1
maxSeq = (1 << seqBits) - 1
nodeShift = seqBits
timeShift = seqBits + nodeBits
)
// 2025-01-01T00:00:00Z
const customEpoch int64 = 1735689600000
type Generator struct {
mu sync.Mutex
lastMs int64
seq int64
nodeID int64
clock Clock
}
func NewSnowflakeGenerator(nodeID int64, clock Clock) *Generator {
return &Generator{
lastMs: -1,
seq: 0,
nodeID: nodeID,
clock: clock,
}
}
func (g *Generator) Next() int64 {
g.mu.Lock()
defer g.mu.Unlock()
now := g.clock.Now().UnixMilli()
if now == g.lastMs {
if g.seq < maxSeq {
g.seq++
} else {
now = WaitNextMillis(g.clock, g.lastMs)
g.lastMs = now
g.seq = 0
}
} else {
g.lastMs = now
g.seq = 0
}
ts := int64(g.lastMs - customEpoch)
return (ts << timeShift) |
(g.nodeID << nodeShift) |
g.seq
}
And with that I was able to pass the challenge just fine. You can check the full solution to the challenge here.
#distributed-systems #snowflake #unique-id-generation #go #maelstrom